
Ars Technica
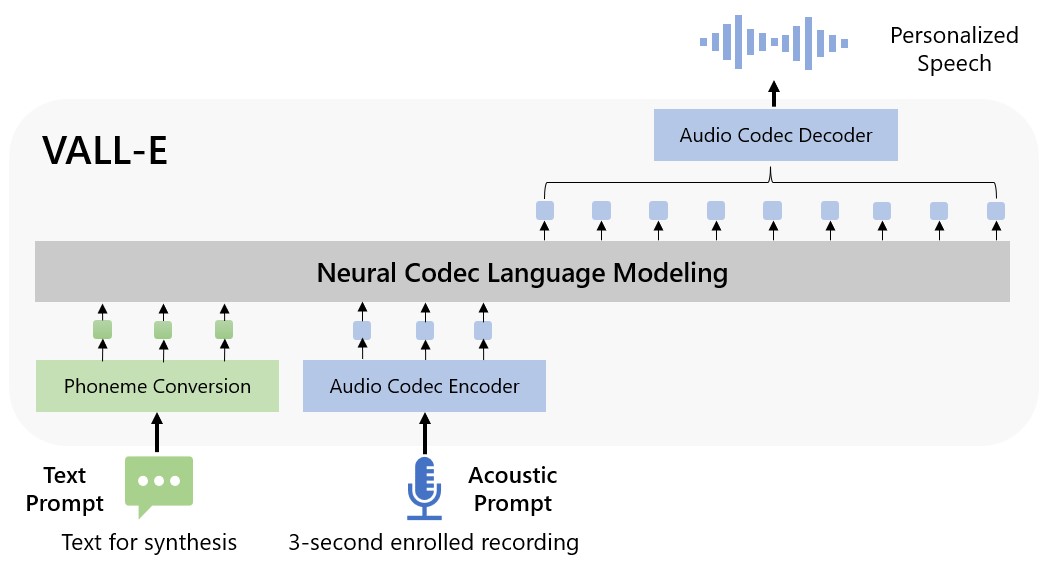
On Thursday, Microsoft researchers announced a new text-to-speech artificial intelligence model called Val-E It can closely mimic a person’s voice when given a three-second audio sample. Once it has learned a specific sound, VALL-E can synthesize the sound of that person saying anything – and do so in a way that tries to preserve the speaker’s emotional tone.
Its creators anticipate that VALL-E can be used for high-quality text-to-speech applications, speech editing where a recording of a person can be edited and altered from a text transcript (making them say something they didn’t originally), and audio content creation when combined with other AI models such as GPT-3.
Microsoft calls VALL-E a “neural coding language paradigm,” and it’s built on a technology called EnCodec, declared dead in October 2022. Unlike other text-to-speech methods that usually synthesize speech by processing waveforms, VALL-E generates separate phonetic encoders from text and voice prompts. It basically analyzes what a person sounds like, breaks that information down into separate components (called “codes”) thanks to EnCodec, and uses the training data to match what it “knows” about what that person would sound like if they spoke in other phrases outside of the three second sample. Or as Microsoft puts it in a VALL-E PAPER:
For custom speech grouping (eg, non-shot TTS), VALL-E generates the corresponding voice codes modal to the recorded 3-second recording voice codes and the voice prompt, which constrain the speaker and content information respectively. Finally, the generated audio codes are used to group the final waveform with the corresponding neural decoder.
Microsoft trained VALL-E’s speech synthesis capabilities into a sound library, compiled by Meta, called Libre Lite. It contains 60,000 hours of English speaking from more than 7,000 speakers, mostly pulled from LibriVox Public domain audiobooks. For VALL-E to score well, the sound in the three-second sample must match a sound in the training data.
on vall-e Website exampleMicrosoft provides dozens of audio examples of an AI model in action. Among the samples, a “speaker prompt” is a three-second sound provided for VALL-E that must be imitated. A “ground truth” is a pre-existing recording of the same speaker saying a particular statement for comparative purposes (sort of like a “control” of an experiment). “Baseline” is an example of synthesis provided through the traditional text-to-speech synthesis method, and the “VALL-E” sample is output from the VALL-E model.
Microsoft
While using VALL-E to generate these results, the researchers just fed a three-second “Speaker Prompt” sample and a text string (what they wanted the voice to say) into VALL-E. So compare the “Ground Truth” sample to the “VALL-E” sample. In some cases, the two samples are very close together. Some of the VALL-E results appear to be computer generated, but others are likely to be mistaken for human speech, which is the goal of the model.
In addition to preserving the speaker’s vocal timbre and emotional tone, VALL-E can also simulate the “acoustic environment” of a voice sample. For example, if the sample came from a phone call, the audio output would simulate the acoustic and frequency characteristics of a phone call in its synthesized output (that’s a fancy way of saying it would sound like a phone call, too). and microsoft samples (in the ‘Synthesis of diversity’ section) showed that VALL-E can generate variations in pitch by changing the random seeds used in the generation process.
Perhaps because of VALL-E’s ability to fuel mischief and deception, Microsoft hasn’t provided VALL-E code for others to try, so we haven’t been able to test VALL-E’s capabilities. Researchers seem aware of the potential social harm this technology could cause. To conclude the paper, they wrote:
“Because VALL-E can synthesize speech that preserves the identity of the speaker, it may have potential risks in model misuse, such as spoofing voice recognition or impersonating a specific speaker. To mitigate these risks, it is possible to build a detection model to discriminate whether or not a specific speaker has been synthesized. Soundtrack by VALL-E. We’ll also put Microsoft Principles of Artificial Intelligence In practice when developing models.

“Freelance web ninja. Wannabe communicator. Amateur tv aficionado. Twitter practitioner. Extreme music evangelist. Internet fanatic.”